Advanced KDB/Q Architecture
In a previous blog post, we covered the Plain Vanilla Tick Setup, a foundational KDB/Q framework that serves as the starting point for more advanced systems. In this post, we’ll explore a more sophisticated architecture and walk through the key design decisions you can make when building a complete KDB/Q stack.
KDB/Q is an incredibly powerful tool, enabling you to build an entire market data capture and analytics platform end-to-end, without needing to piece together multiple technologies. Where other setups might require separate components for real-time streaming, in-memory storage, historical persistence, and analytics, KDB/Q handles it all natively. This simplicity is what makes it so efficient and so powerful.
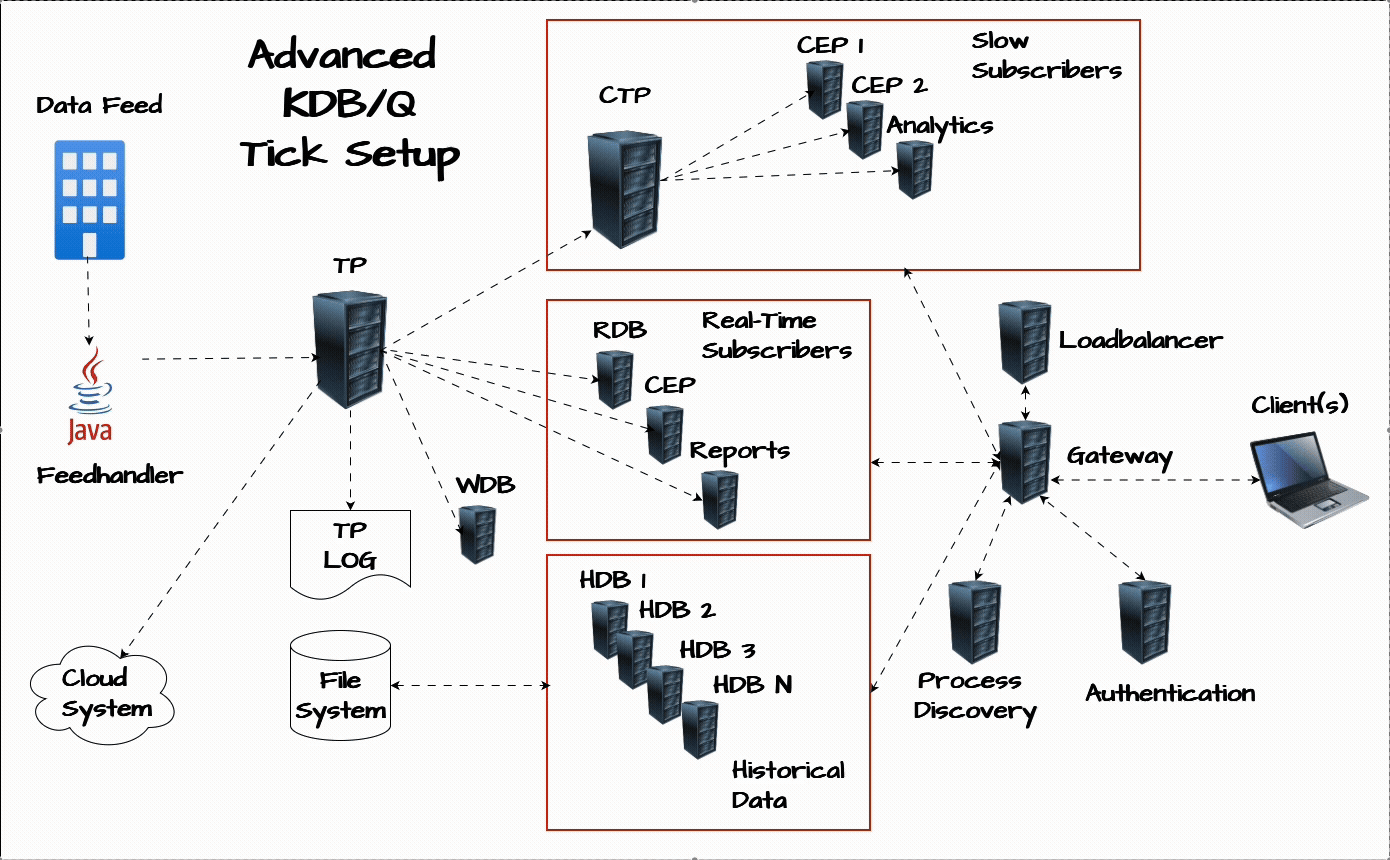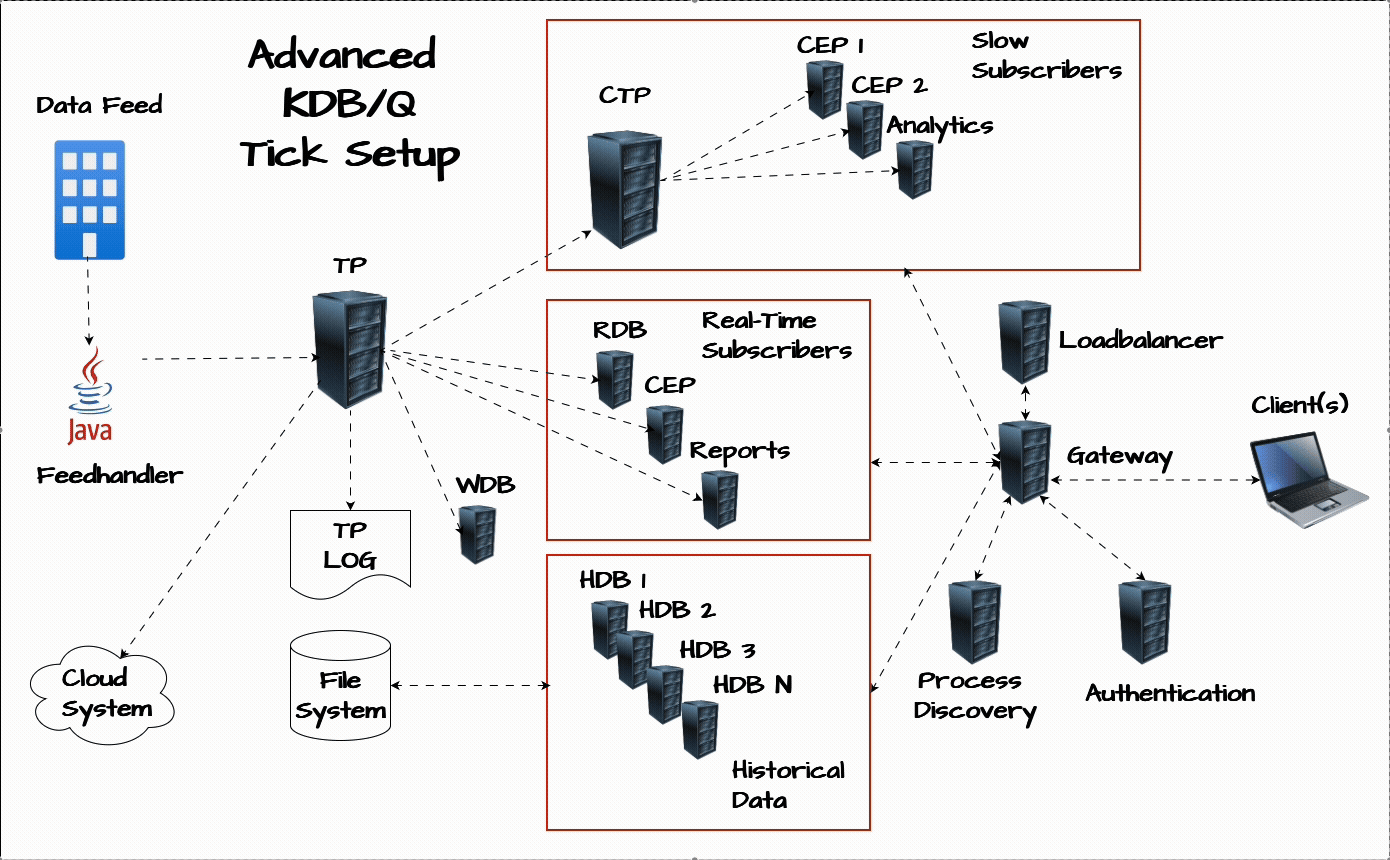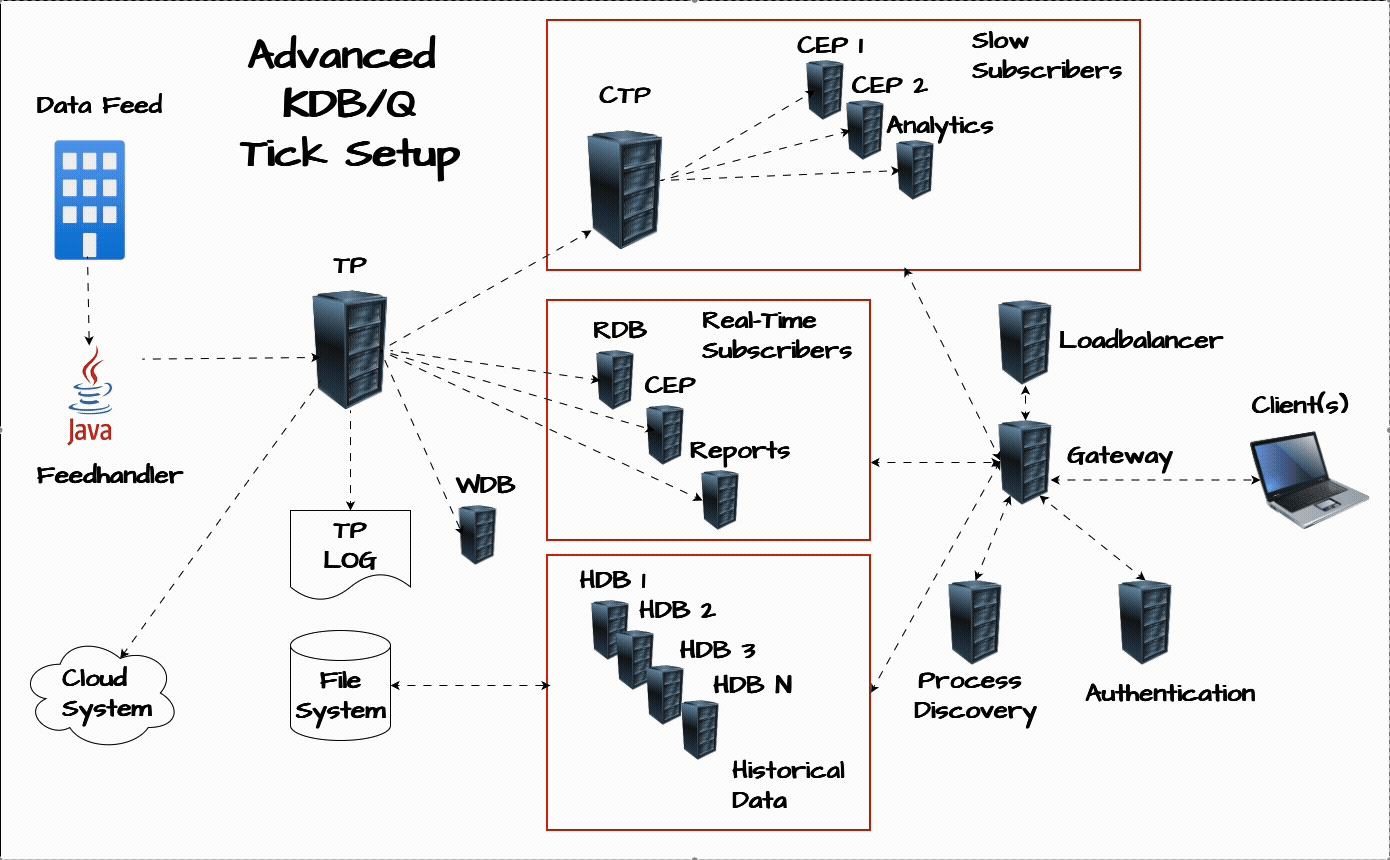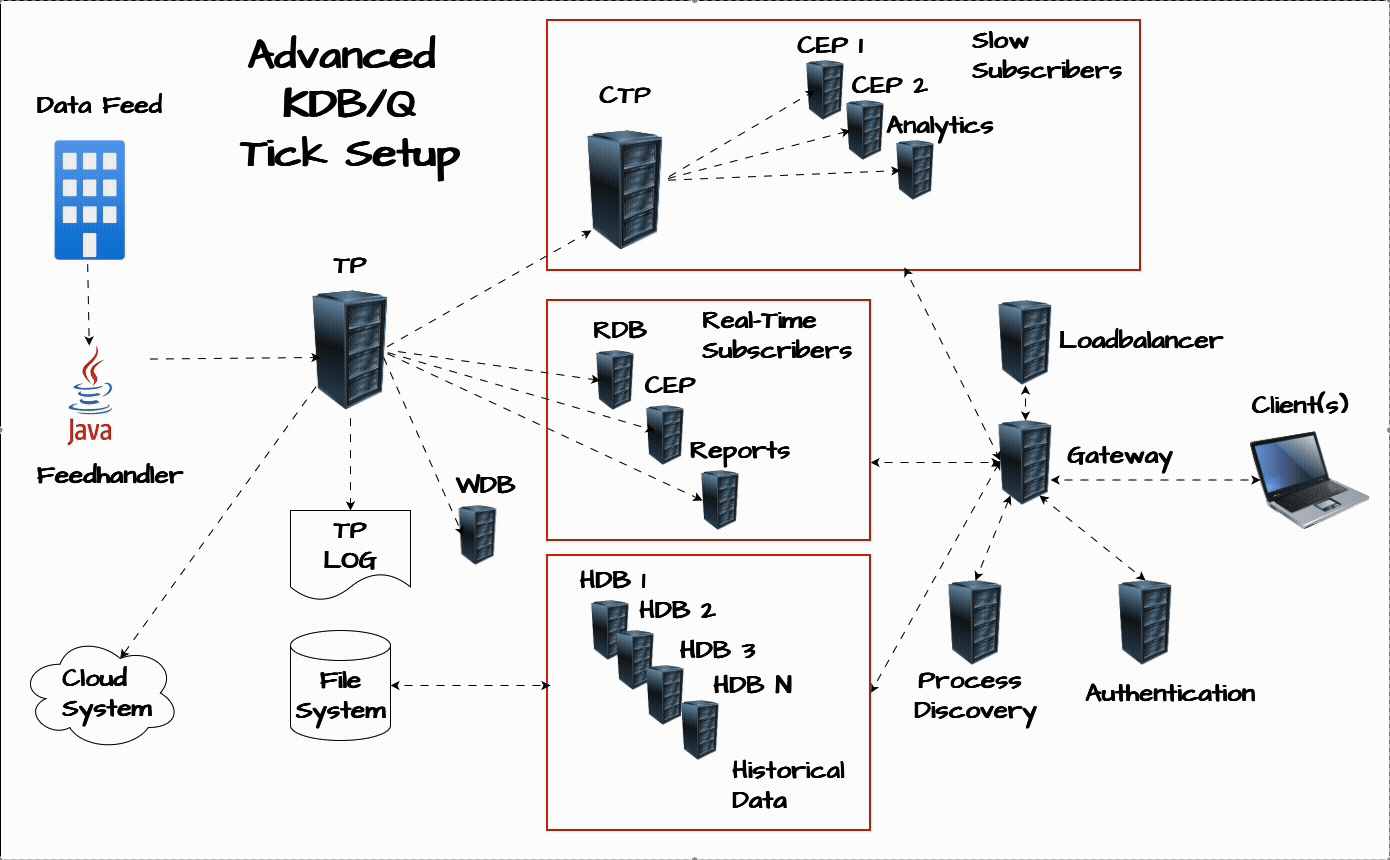
If you’d like a refresher on the plain vanilla tick setup or a step-by-step breakdown of how a KDB/Q Tickerplant works, check out the resources section at the end of this post.
Microservices and Market Data: Designing KDB/Q Systems the Right Way
Before we deep dive into the implementation details of each process in our advanced KDB/Q Tick framework, it’s worth stepping back to explore what good software design really looks like. A key principle of effective architecture is simplicity through separation of concerns. This is where microservices come in. Microservices, often praised as the backbone of modern software architecture, play a vital role in building scalable, maintainable systems. In a microservices-based design, each process is responsible for a single, well-defined task. Nothing more. This modularity not only makes systems easier to understand and debug but also allows for independent development, deployment, and scaling of components.
The benefits? Microservices reduce interdependencies, making your stack more flexible and resilient. If one part fails, it won’t bring down the whole system. It also becomes easier to test and upgrade individual services without affecting the rest. In the context of KDB/Q, this means cleaner data pipelines, clearer logic boundaries, and a more robust architecture, one where each service (e.g., the Tickerplant, the Real-Time DB, the Historical DB) does exactly what it’s supposed to do, and nothing else.
Keeping things simple isn’t just elegant, it’s powerful.
Beyond Plain Vanilla: Enhancing Your KDB/Q Stack with Flavor
With our solid software design principles in place, it's time to explore the key components of a more advanced KDB/Q Tick setup. As we’ve touched on before, KDB/Q is incredibly versatile, so versatile, in fact, that you could technically implement every layer of your data infrastructure using just KDB/Q. The processes outlined below represent just a subset of what's possible. Think of them as the essential building blocks, examples to inspire your own architectural choices as you scale and tailor your system to your specific use case.
Chained Tickerplant: The Lifeguard of Your KDB/Q System
One of the most critical upgrades you can make to your tick architecture is the addition of a chained Tickerplant. Think of it as the lifeguard for your entire setup, its primary role is to safeguard the core of your application: the main Tickerplant. Specifically, it acts as a buffer between the main Tickerplant and any slow subscribers, processes that consume updates more slowly than the Tickerplant generates them. A common example is a Complex Event Processing (CEP) engine running heavy computations. If these processes fall behind, the main Tickerplant’s output queue starts to grow, putting the server under memory pressure. Left unchecked, this can lead to catastrophic failure, the Tickerplant crashes. A chained Tickerplant absorbs that risk by offloading the pressure, ensuring that slow consumers don’t compromise system stability.
The chained Tickerplant connects to the main Tickerplant and redistributes data at a lower frequency, giving slower subscribers more time to process updates. By decoupling them from the main data flow, it ensures that any delays on their end don’t affect the central system. Even if one of these downstream processes continues to lag, only the chained Tickerplant is affected, safeguarding the stability and performance of your primary infrastructure.
Complex Event Processing (CEP): Real-Time Analytics at the Core
The CEP engine is one of the most versatile components of a KDB/Q architecture. It processes real-time data on the fly to compute analytics that power dashboards, trading strategies, and internal reports. Whether it's calculating Volume Weighted Average Price (VWAP), Time-Weighted Average Price (TWAP), Trade Cost Analysis (TCA), Open High Low Close (OHLC) bars, or running rolling analytics, a CEP can provide immediate insight into what’s happening in the market.
Thanks to KDB/Q’s in-memory capabilities and high-speed computation, all this logic can be executed in a single process, making it extremely efficient and easy to maintain. You can even extend your CEP to cache data for low-latency access, generate alerts, or pre-calculate common queries that your users rely on, turning it into a powerhouse of real-time intelligence.
Write Database (WDB): Scale Beyond Memory Constraints
As the amount of incoming data grows, it's only a matter of time before your server’s memory reaches its limits. That’s where the Write Database comes in. Acting as an intraday persistence layer, the WDB captures incoming data throughout the trading day and writes it to disk in chunks, preventing memory overflows.
This strategy not only protects your system from resource exhaustion but also serves as a fail-safe mechanism. In case your real-time processes go down, the data already written to disk by the WDB can be reloaded and recovered. It also allows for a decoupling of real-time and historical processes, increasing the flexibility and scalability of your infrastructure.
Authentication Service: Control Access with Precision
In a financial environment, not all data is for everyone. Whether it’s compliance requirements or competitive advantage, access control is a must. A dedicated Authentication or Entitlement Service built in KDB/Q enables you to manage user permissions down to the table, column, or even record level.
This service can sit between your Gateway and your backend processes, intercepting every query to ensure it’s coming from an authorized user. You can easily plug this into existing LDAP, OAuth, or custom identity providers, offering robust security with minimal latency. It's your first line of defense in protecting sensitive information in a high-speed world.
Process Discovery Service: Dynamic by Design
As your KDB/Q system grows, hardcoding hostnames and ports becomes a maintenance nightmare. A Process Discovery Service addresses this by acting as a central registry for all processes in the system. Each process, when started, registers itself along with relevant metadata like service type, host, and port.
This dynamic setup allows new processes to join and leave the ecosystem without requiring a restart or manual config updates elsewhere. Clients and services can query the registry in real-time to discover the current location of dependencies, making your system more modular, scalable, and fault-tolerant.
Load Balancer: Evenly Spread the Load
Scaling horizontally often means running multiple instances of the same type of process, like several Historical Databases (HDBs) reading from the same source. A load balancer keeps track of how busy each of these instances is and intelligently routes queries to the one with the most available capacity.
This not only improves performance by preventing bottlenecks but also builds in redundancy. If one instance goes down or becomes too slow, the load balancer can reroute traffic to healthier instances without any manual intervention. It’s an essential component for ensuring high availability and smooth user experiences under load.
Gateway: The Gatekeeper of Your KDB/Q Ecosystem
Second only to the Tickerplant, the Gateway is one of the most critical components of a well-architected KDB/Q system. It provides a single point of entry for users and clients, abstracting away the underlying complexity of your infrastructure. Instead of exposing individual services or databases, the Gateway handles routing, access control, and query validation.
This abstraction not only simplifies client integration but also improves security and maintainability. Want to migrate a database or restructure your services? No problem! Clients keep talking to the Gateway while you change things behind the scenes. Add logic to verify user entitlements, check for required date filters in HDB queries, and aggregate responses from multiple services before returning the result. The Gateway is your command center.
Conclusion
In conclusion, the flexibility and performance of KDB/Q make it one of the most powerful tools in the world of real-time data processing. As we've seen, it allows you to build virtually any component you need, from real-time analytics engines to authentication layers, dynamic routing services, and scalable storage solutions, all within a unified language and runtime. The processes outlined above are just a glimpse into what’s possible. They form the backbone of a more advanced, modular KDB/Q tick architecture, but they are by no means exhaustive.
At the end of the day, there’s no such thing as a one-size-fits-all framework. Your system should reflect your specific use case, data volumes, latency requirements, and business goals. The beauty of KDB/Q is that it gives you the freedom to design your architecture exactly the way you need it, lean and simple or sophisticated and resilient. Build smart, scale wisely, and let the language do the heavy lifting.
Resources: