Gateways: The Bouncer at the Front Door of Your KDB/Q Stack
Why They Matter, How They Work, and How to Build One That Actually Scales
In every KDB/Q stack you have ever built, somewhere behind the scenes there’s likely been that conversation:
"Hey, where do I find the options data?"
"Why did my query lock up the HDB?"
"I swear I didn’t break anything..."
If you have ever been on the receiving end of questions like these, or if your users have occasionally accidentally brought your system to its knees, you are living proof that a missing (or poorly implemented) gateway is a costly architectural gap.
In this post, we will answer the big question:
What is a Gateway, and why is it such a critical component in modern KDB/Q architecture?
We will break down best practices, real design options, and even extend the classic ideas with modern approaches like async routing, caching, security, and observability.
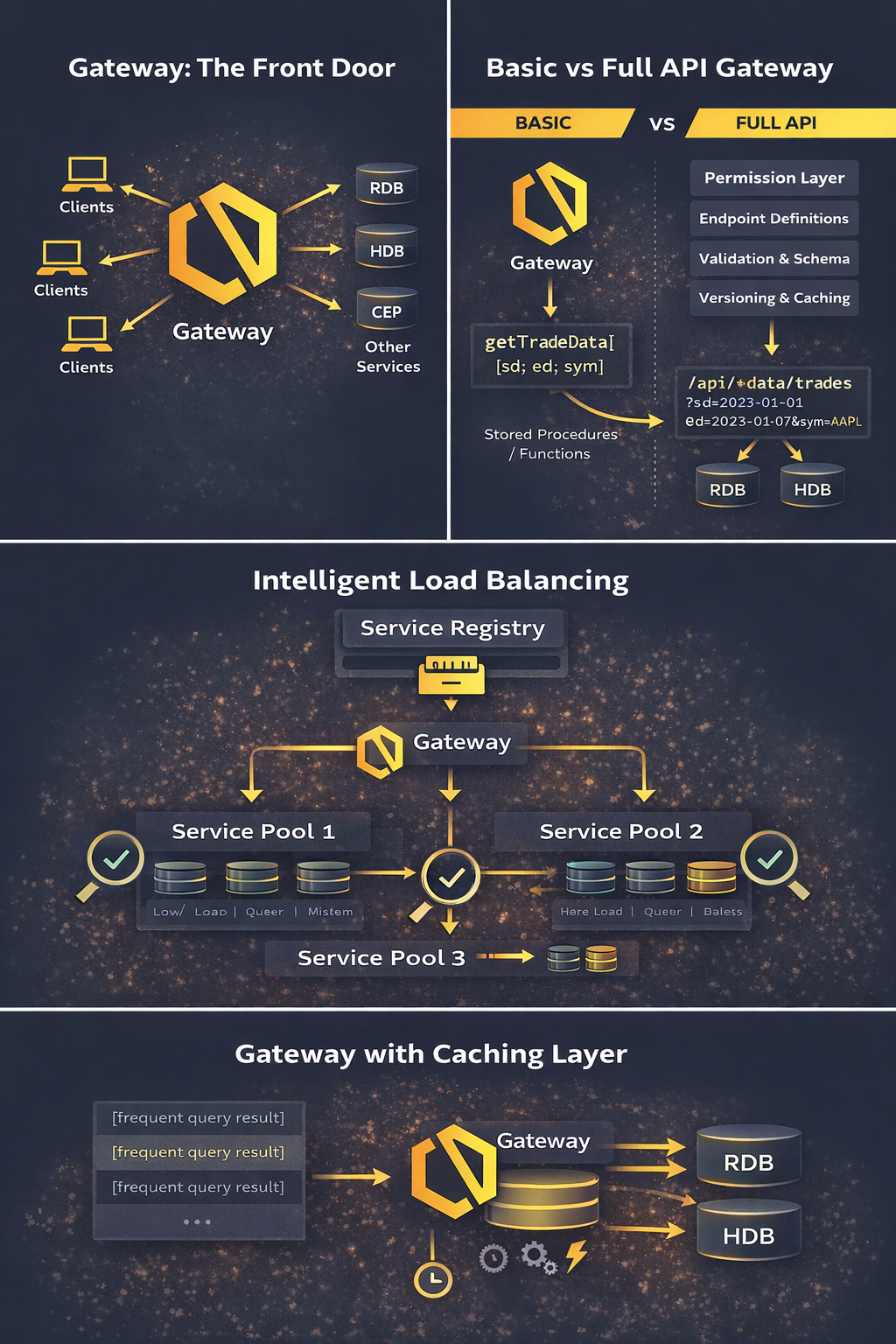
What Is a Gateway?
The way I like to think about a gateway is as the single point of entry for all clients interacting with your KDB/Q system. But it’s not just an access point, it's much more than that. A gateway acts as a protective layer for your stack: it shields your system from poorly formed or expensive queries, verifies who is allowed to query what, blocks requests when necessary, and routes valid queries to the correct endpoint.
Just as importantly, a gateway removes a whole set of responsibilities from your users. They no longer need to
- Know where the data lives (RDB vs HDB vs other services)
- Understand how to combine results from multiple sources, or
- Send several requests and stitch the responses together themselves.
In other words, the gateway is your bouncer at the front door of the KDB/Q stack, checking IDs, enforcing the rules, and making sure only the right requests make it inside.

Clients make one call to the gateway, and magic happens behind the scenes:
- Data is retrieved from the correct services
- Requests are load balanced if needed
- Security and permissions are enforced
- A clean, unified result is returned
This separation is powerful. It decouples client logic from system internals, which means you can evolve your architecture without constantly breaking downstream users. You can move data, split databases, add replicas, or introduce new services, and the client never needs to know. From their perspective, the gateway is the system.
Gateway Roles and Responsibilities
Thinking of a gateway purely as an access point is selling it short. Yes, it is the single entry point for all clients interacting with your KDB/Q stack, but more importantly, it’s the place where intent is translated into action. Clients express what they want, not how or where to get it. The gateway takes responsibility for figuring out the rest.
1. Access Interface
The access interface defines how clients interact with your KDB/Q system, and predictability here is everything. A gateway should expose a small, well-defined set of entry points that clients can rely on, whether that’s through KDB/Q function calls, stored procedures, or endpoints for non-q consumers. By enforcing a consistent request structure, the gateway reduces ambiguity, simplifies client implementations, and prevents users from crafting ad-hoc queries that bypass system rules. A clear access interface also makes it easier to validate inputs, apply permissions, version APIs, and evolve the backend without breaking consumers. In short, the gateway turns an otherwise flexible and potentially dangerous system into something stable, consumable, and safe to use.
2. Authentication, Authorization, and Entitlements
Security in KDB/Q systems often starts, and ideally ends, at the gateway. Before talking to any service, it verifies:
- User identity
- What they are allowed to request
- Whether the operation is permitted under current policy
This is often done with functions like .z.pw, .z.pg, or .z.ps to gate specific tables, symbols, or services without exposing internals. Rather than spreading entitlement logic across multiple processes, the gateway centralizes access control in one place. This includes verifying who the user is, what they are allowed to see, and which operations they are permitted to perform.
From a design perspective, this dramatically simplifies the rest of the stack. Downstream services can assume that incoming requests are already authorized and well-formed. From an operational perspective, it gives you a single point to audit access, apply changes, and reason about who touched what data and when.
In larger systems, however, avoiding bottlenecks and single points of failure becomes critical. Following the one process, one task principle, it can make sense to introduce a dedicated, centralized entitlements service that gateways can query as needed. This keeps authorization logic decoupled, easier to maintain, and simpler to evolve over time. As with most architectural decisions, there’s no one-size-fits-all solution, the right approach depends on scale, complexity, and operational requirements.
3. Routing Queries to the Right Endpoint
In a non-trivial KDB/Q system, data rarely lives in just one place. Recent data may sit in an RDB, historical data in one or more HDBs, and derived analytics in separate services altogether. Expecting clients to understand this layout is both unrealistic and dangerous. The gateway abstracts this complexity away. Based on query parameters, such as date ranges, instruments or asset classes, it decides which backend service (or combination of services) should handle the request. The routing logic can be as simple or as sophisticated as your system requires, but the key point remains the same: clients should never need to care.
4. Load Balancing and Backpressure Management
As usage grows, the gateway also becomes a strategic control point for managing load. Whether you’re serving more users, running heavier analytics, or supporting extended trading hours, a single process handling all requests will eventually become a bottleneck. Load balancing is how you scale horizontally without rewriting your entire system. In a KDB/Q context, load balancing typically means running multiple instances of the same service, most commonly HDBs, analytics services, or even gateways themselves, and distributing incoming queries across them. Because KDB/Q processes are lightweight and fast to start, spinning up additional instances is often far easier than vertically scaling a single, overworked process. A load balancer can track process health, query latency, or simple round-robin allocation to ensure work is spread evenly and no single process is overwhelmed.
A well-designed gateway architecture doesn’t just route queries; it distributes them intelligently. Load balancing ensures that requests are spread evenly across available resources, be that multiple RDBs, HDBs, or downstream analytic services, so no single process becomes a bottleneck. There are a few approaches you can take:
- Round-robin: The simplest method, each request goes to the next available process in line. Great for evenly distributed workloads.
- Least-loaded: The gateway keeps an eye on real-time processes and routes queries to the node with the most capacity.
- Data-locality aware: Particularly in mult-database environments, the gateway can send queries to the node closest to the data, minimizing network latency and improving throughput.
But load balancing isn’t just about performance, it’s also about resilience. If one node becomes unresponsive, the gateway can detect the failure, reroute queries, and keep the system alive without users even noticing. This combination of performance optimization and graceful degradation turns your gateway from a mere traffic cop into a full-fledged air traffic controller, keeping everything flowing safely and efficiently.
Much like entitlements, load balancing can be handled in two ways: either as a dedicated, standalone service, or by embedding the load-balancing logic directly within the gateway itself.
And remember: a gateway without load balancing is like a London pub with only one bartender on a Friday night, it might technically work, but no one’s going to have a good time.

5. Data Aggregation
Sometimes a single request needs data from more than one place, for example, combining historical data from the HDB with live updates from the RDB. In these cases, the gateway acts as the orchestrator: it fans out the request to the relevant backends, aggregates and reconciles the results, and composes a single, consistent response before returning it to the client. This keeps the client interface simple while hiding the underlying complexity of the data landscape.
Gateway Design Options
As usage increases, the gateway evolves beyond a simple entry point into your KDB/Q stack and starts acting as a coordinator, opening up a range of different architectural and design choices. It is worth keeping in mind that there’s no single “right” way to design a gateway. Different problems call for different solutions, so the shape of your gateway should always be driven by the actual needs of your system. Before settling on a design, it’s useful to step back and ask a few fundamental questions:
- What query volume does the gateway need to sustain?
- How many clients connect, and are they humans, automated services, or a mix of both?
- How many downstream processes does the gateway orchestrate (RDBs, HDBs, CEP engines, etc.)?
- Are those processes distributed across multiple servers or even multiple regions?
- Will there be a single central gateway, or several gateways working in parallel?
- What are the requirements around resilience and business continuity?
- How are queries expressed and executed?
- How are results returned? Does the gateway need to merge or aggregate data before responding?
Answering these upfront will naturally guide you toward a gateway design that fits your use case, rather than forcing your use case to fit the design. In the next section, we will look at two different approaches outlined in KX’s "Common Design Principles for kdb+ Gateways, and walk through the benefits and trade-offs of each.
Pass-Through Gateway
This is the simplest pattern. When the gateway gets a request it passes it straight to a dedicated load balancer. That balancer then picks the least busy backend service and returns the result, back through itself, to the gateway. Think of it like a traffic cop taking the request, deciding the best lane, and handing you back the response.
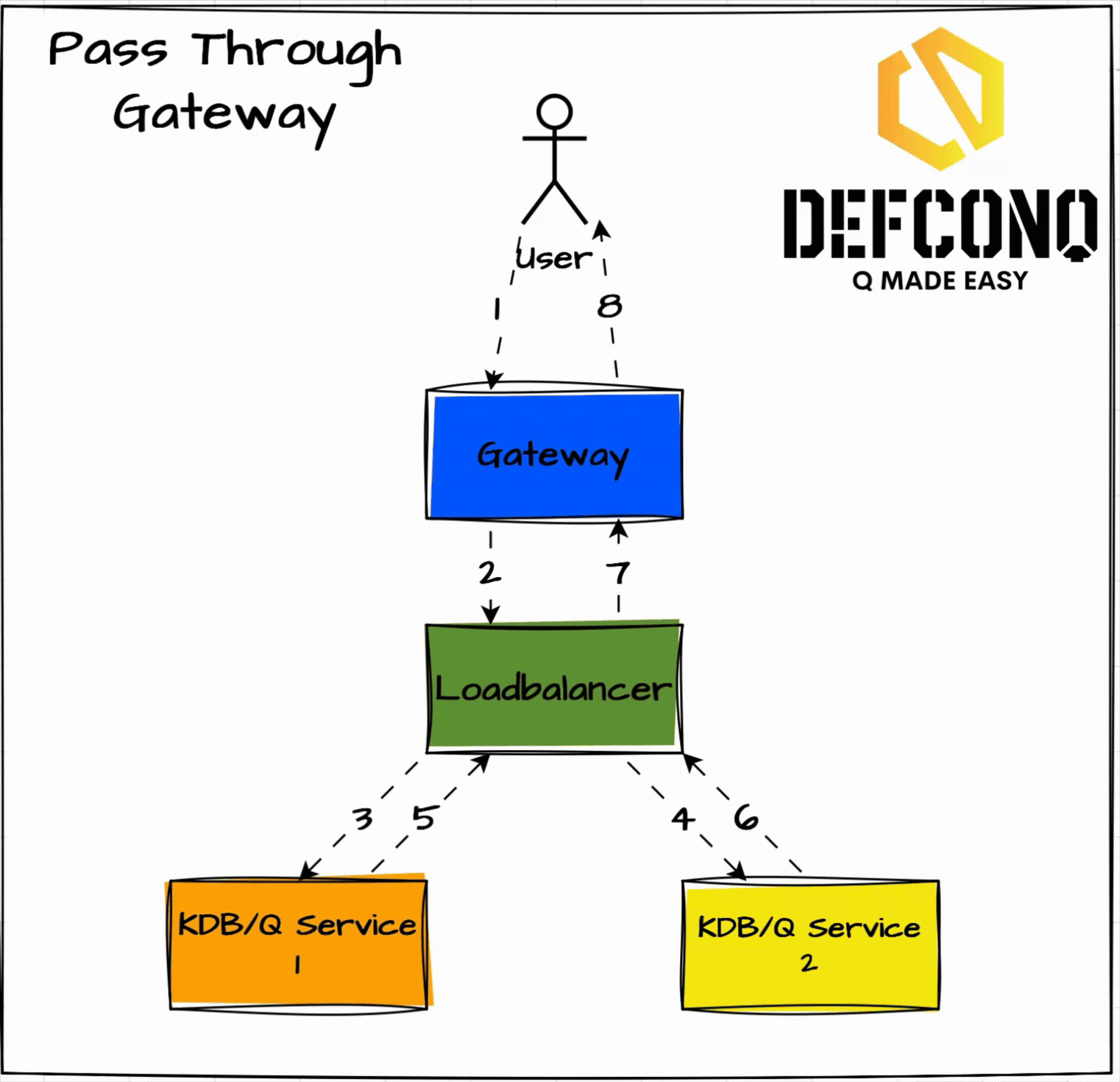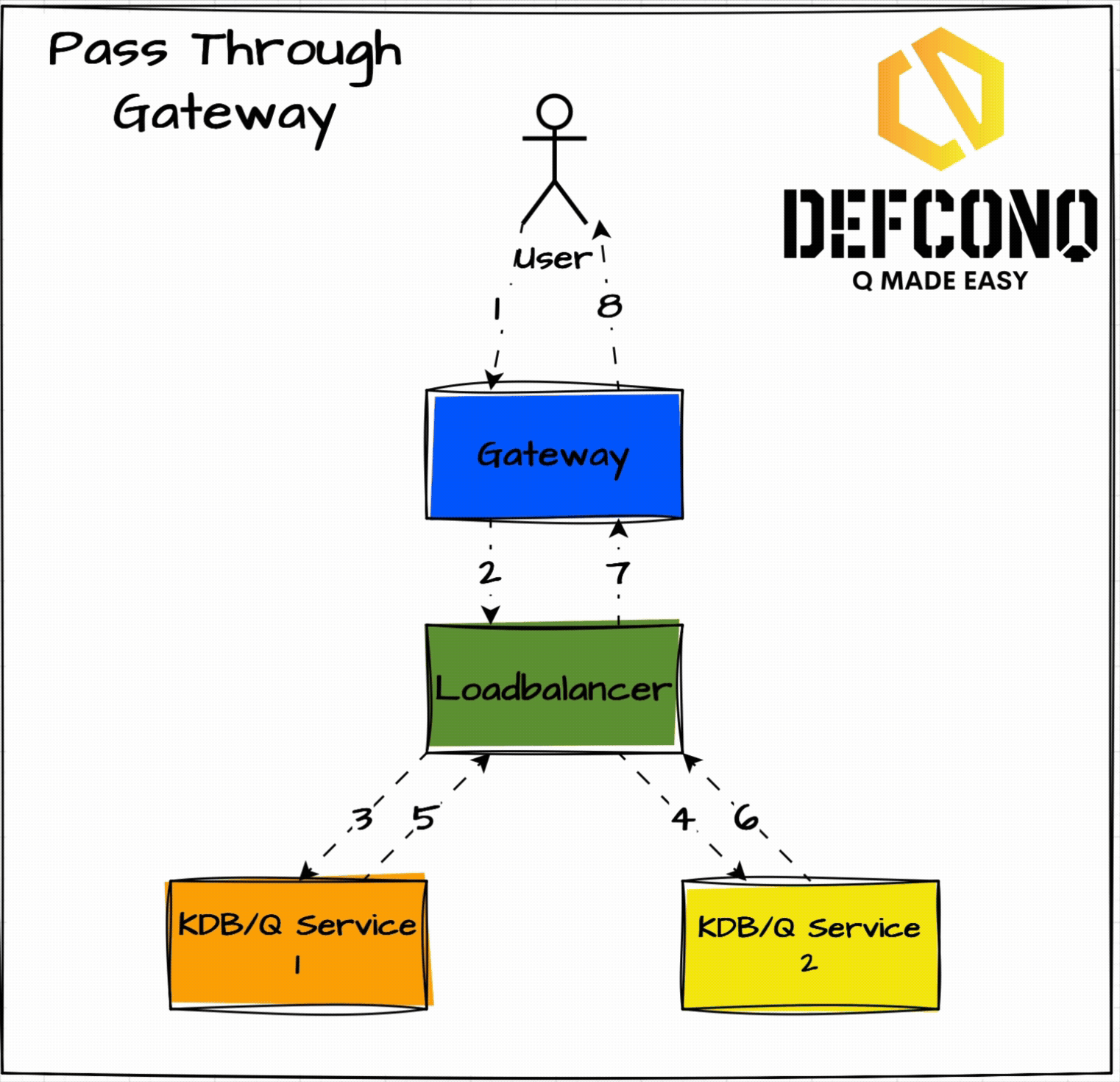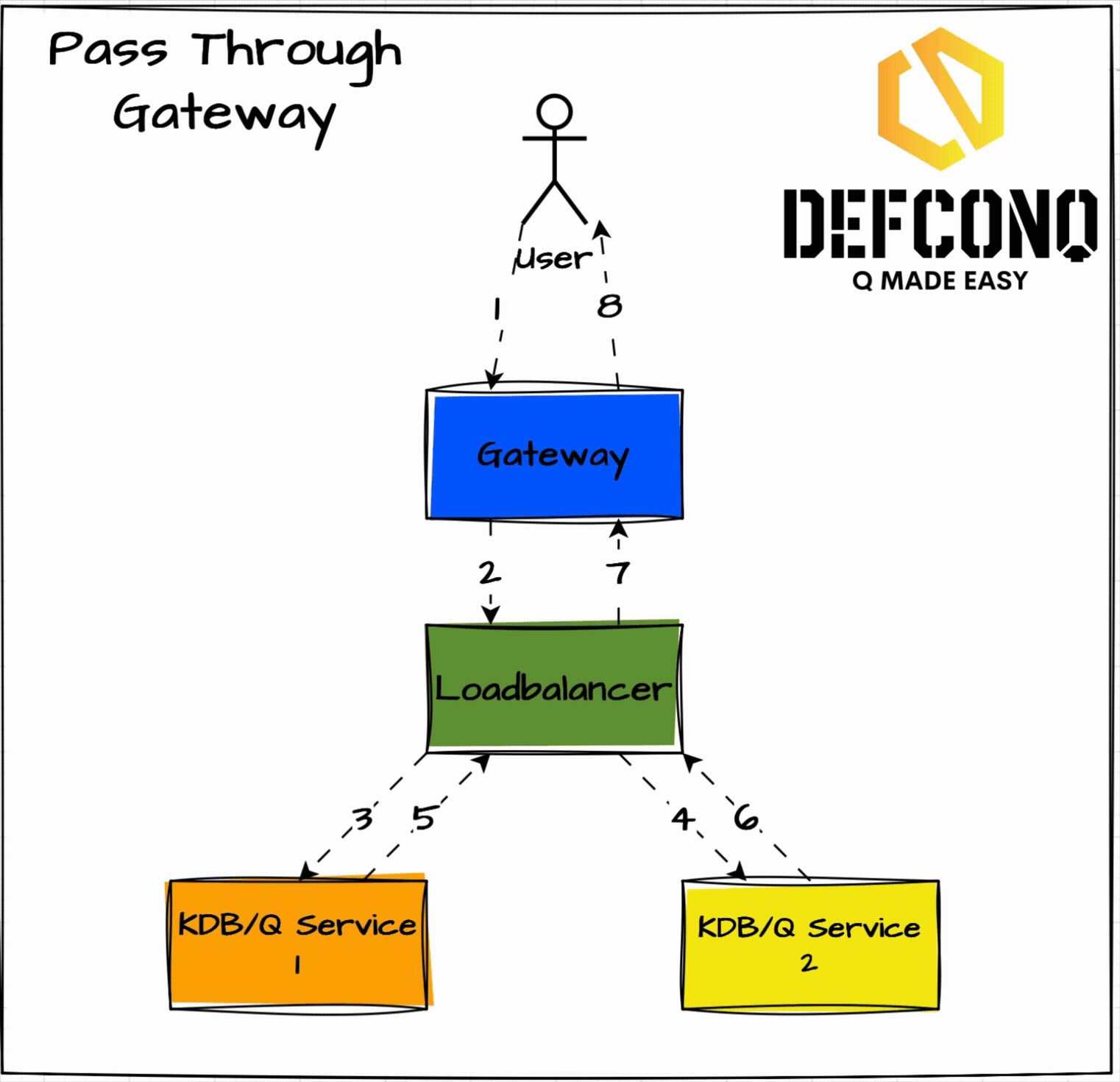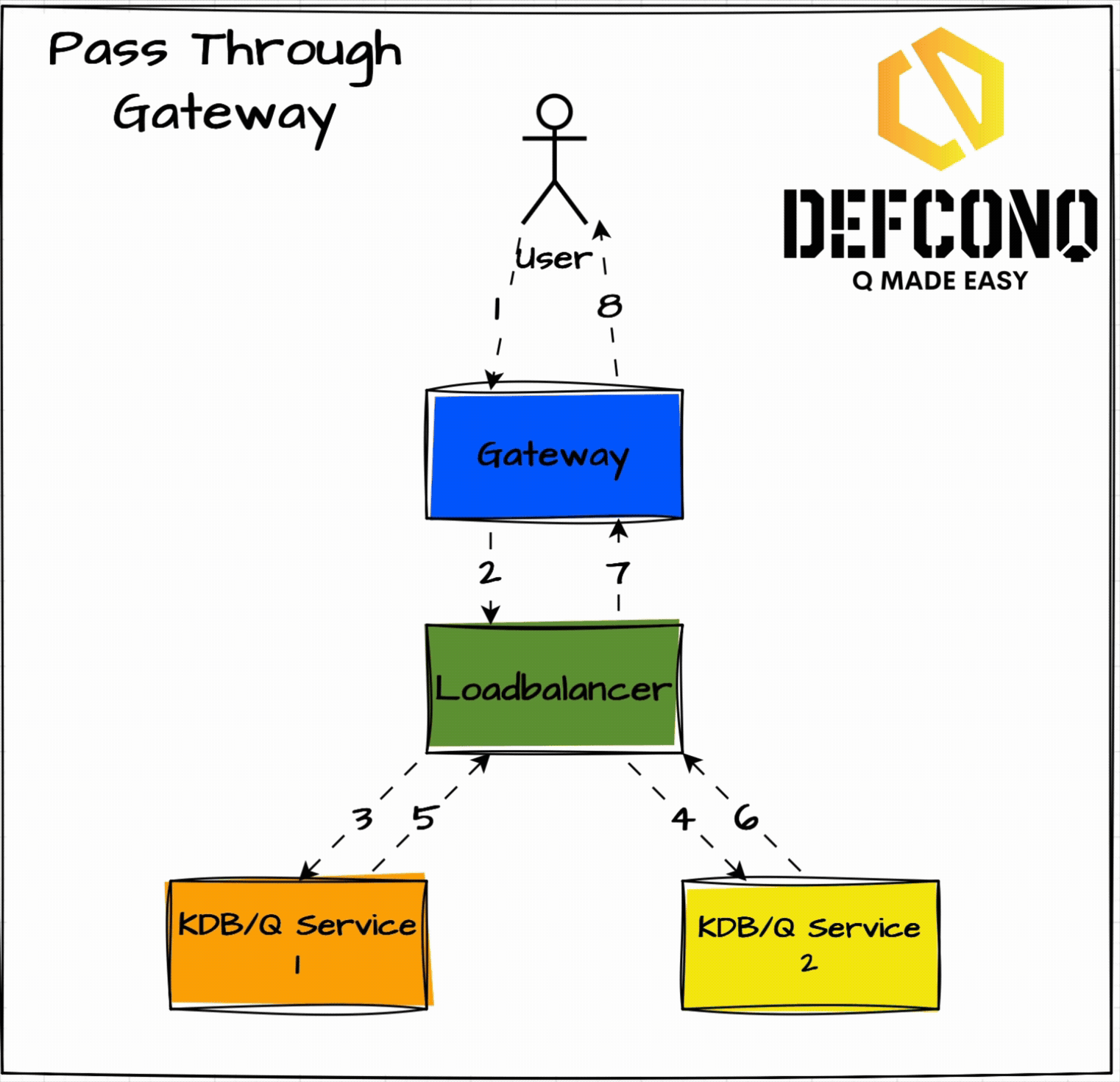
Pros
- Simple logic.
- Backend choice is based on load.
Cons
- Extra hop adds overhead.
- Every response flows back through the balancer (extra IPC).
When this works
- Very simple systems
- Use of External load balancers (L4/L7)
- You don’t care about extra IPC hops
Why it often hurts
- Extra latency (double IPC)
- Load balancer becomes hot very quickly
- Harder to introspect query lifecycle from the gateway
In KDB/Q terms: it works, but it’s rarely elegant.
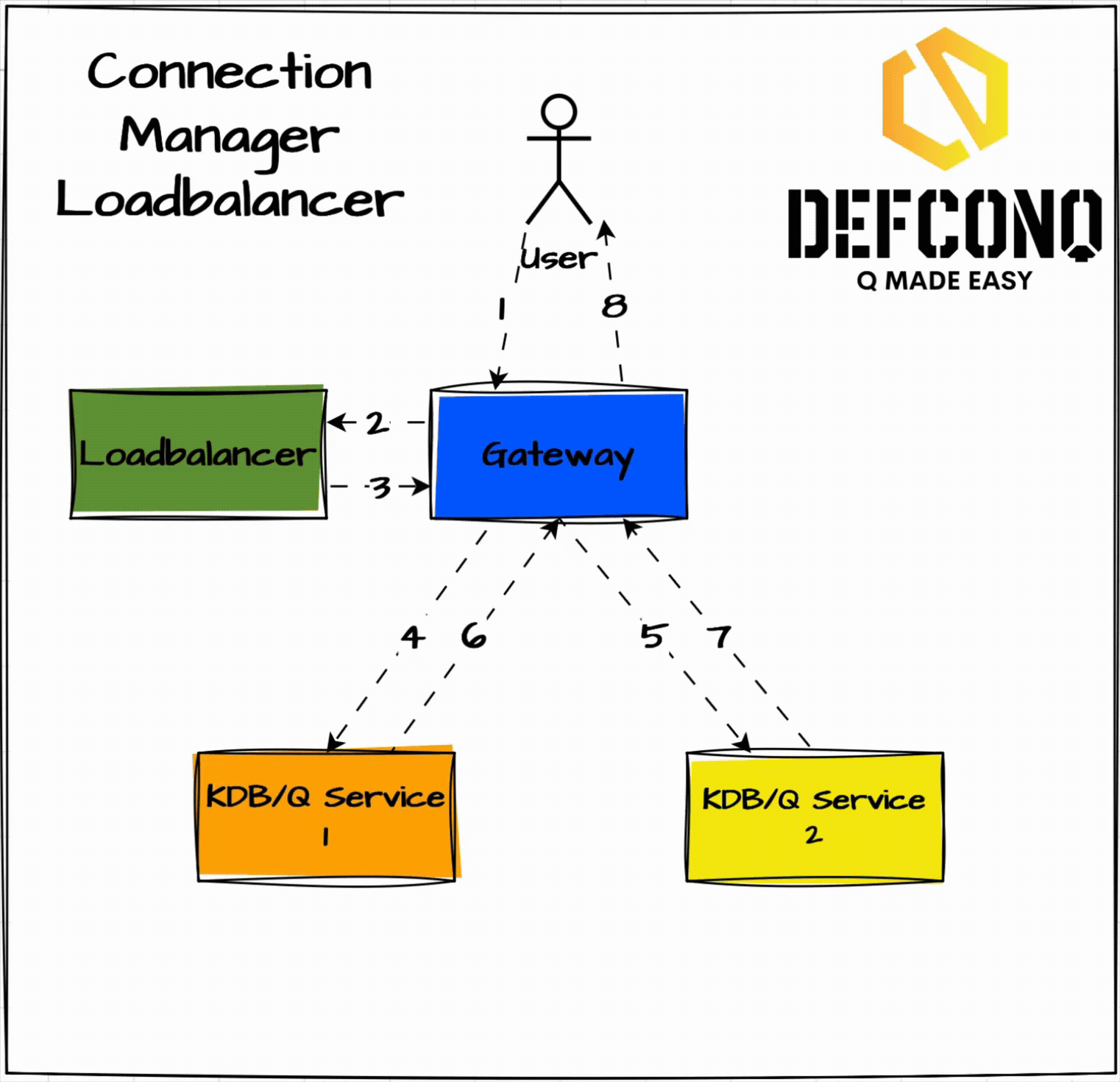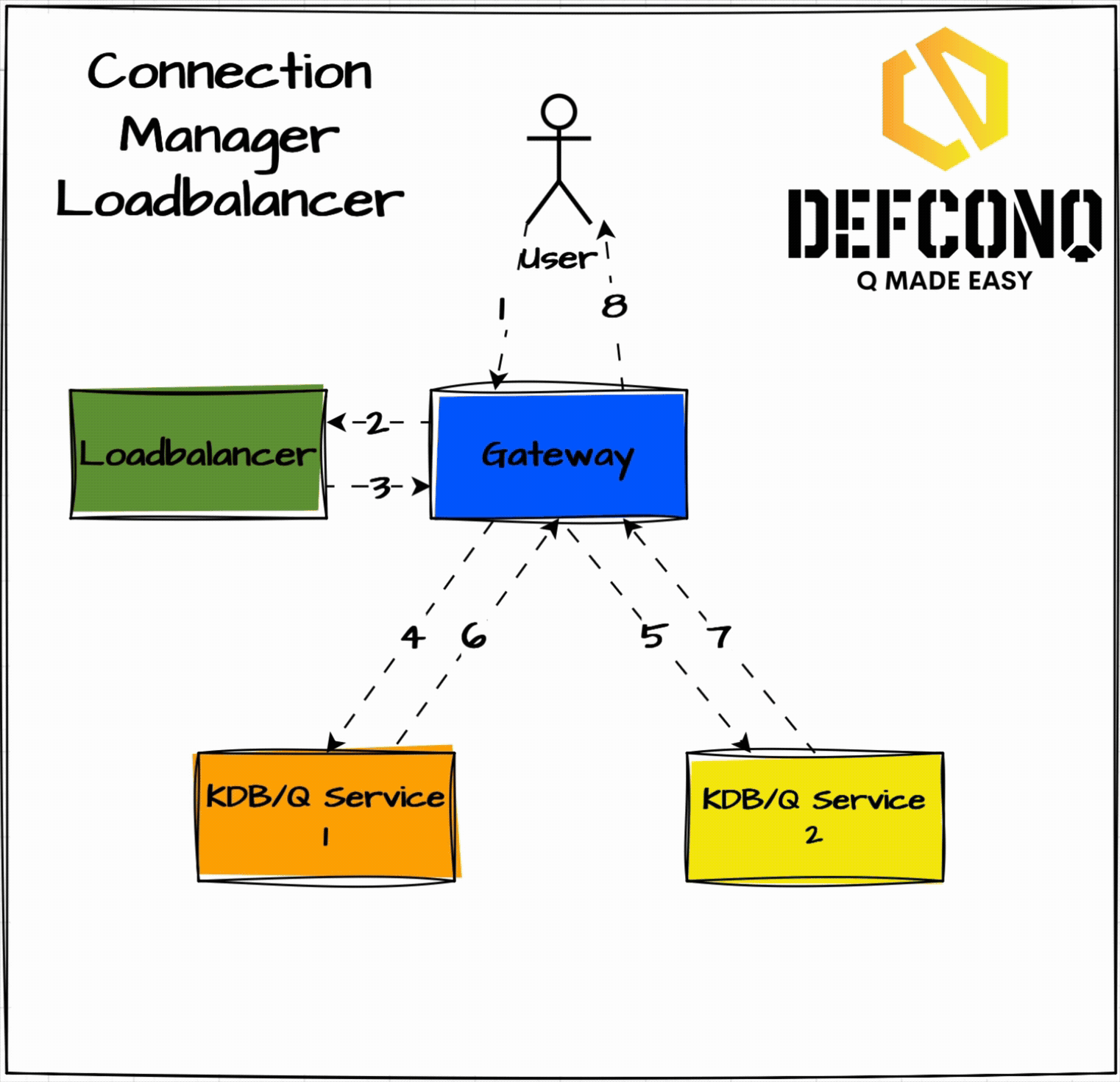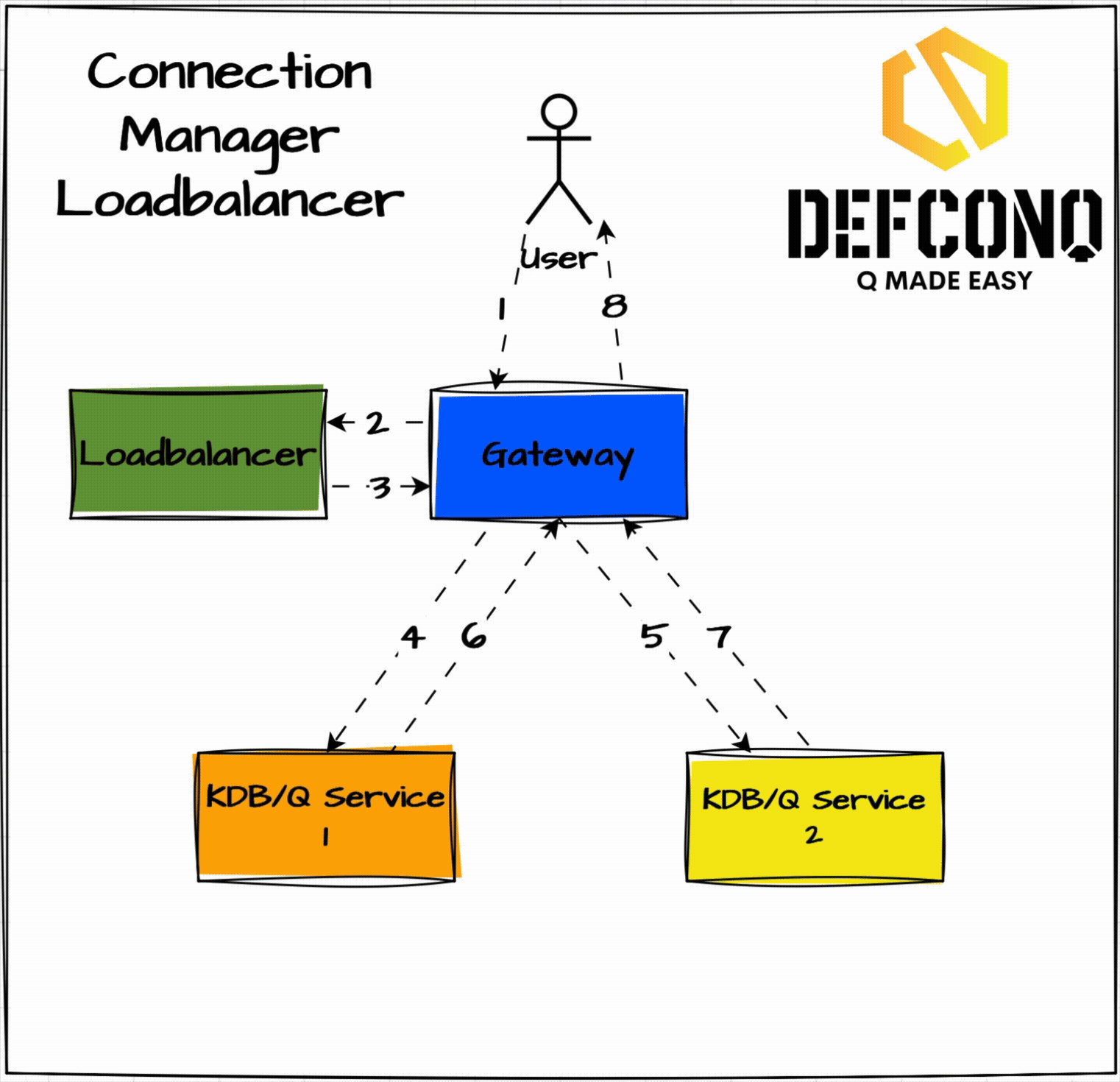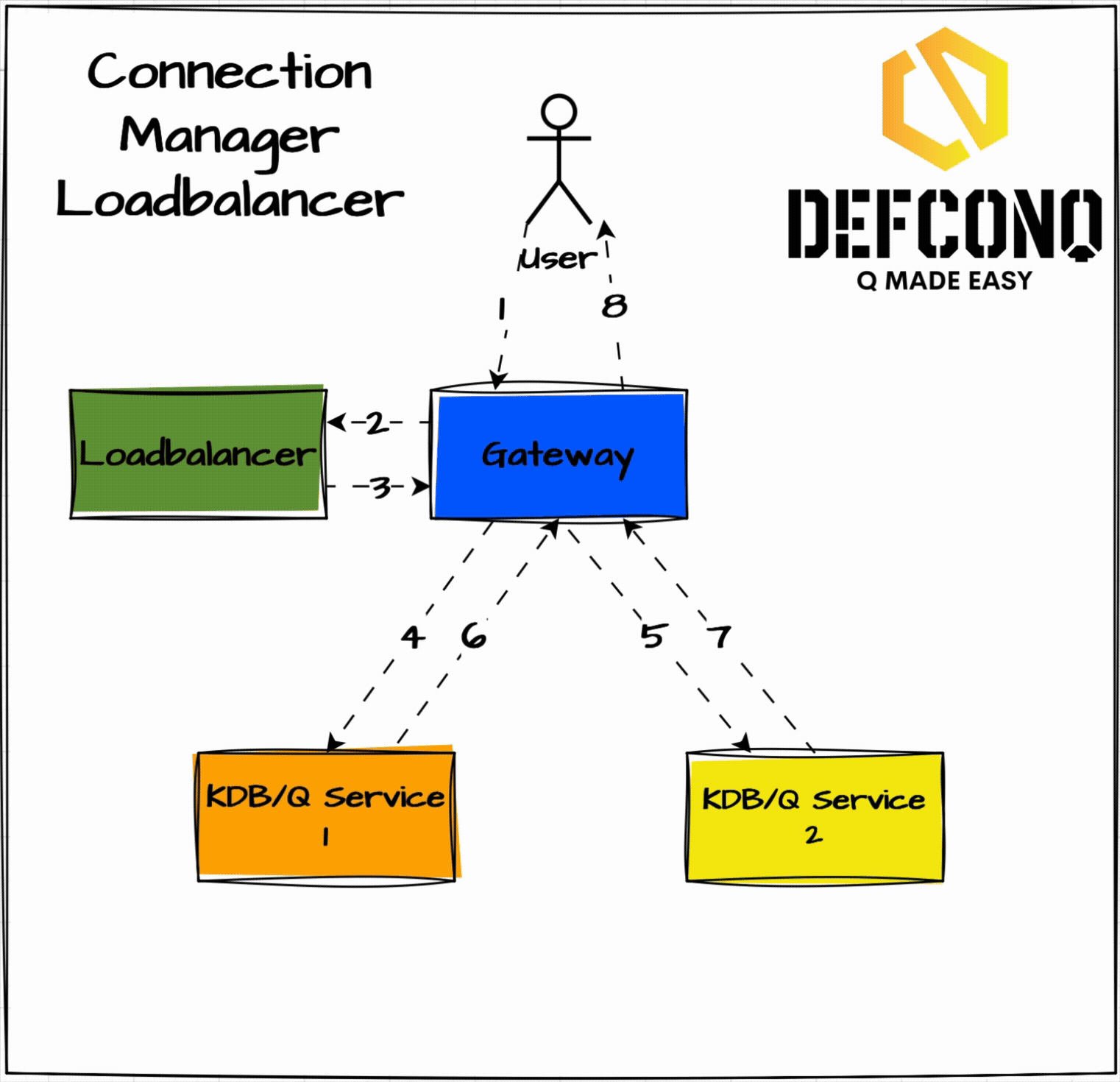
Connection-Manager Load Balancer (Recommended)
This approach splits responsibility a bit more smartly. The gateway asks the load balancer: "Give me the address of a service that can run this query." The Loadbalancer responds with a host:port, and then the gateway talks directly to that service for both request and result. You can implement this two ways:
- Round-Robin: simple rotation through services.
- Availability-Aware: only return a service if it’s currently free, otherwise queue the request until one becomes free.
The latter is more work, but it’s way better at keeping services busy and minimizing unnecessary queueing. These more advanced gateways go one step further by actively maintaining a service registry and continuously tracking the state of the underlying services. Instead of blindly rotating requests, the gateway makes informed routing decisions based on factors such as service availability, current system load, and the expected complexity of the incoming query. A lightweight lookup determines which process is free, which one is already under pressure, and which is best suited to handle the work at hand. This moves the system well beyond simple round-robin scheduling and results in lower tail latencies, better overall throughput, and significantly improved resource utilisation across the entire KDB/Q stack.
Key Takeaways
| Pattern | IPC Overhead | Resource Utilization | Complexity |
|---|---|---|---|
| Pass-Through | High | Moderate | Low |
| Connection Manager (Smart) | Low | High | Medium-High |
For smaller deployments or proof-of-concepts, simple round-robin might suffice. But at real scale — where queries run concurrently and durations vary, having the load balancer actually track service state and manage queues is worth the engineering investment.
Beyond the Basics: Key Considerations for Advanced Gateway Design
As your platform scales and the architecture becomes more sophisticated, the gateway naturally evolves with it. What started as a simple entry point now takes on more responsibility and nuance. In this section, we will look beyond the basics and explore a set of additional considerations that come into play when designing more advanced gateways, and how to approach them in practice.
Synchronous vs. Asynchronous Communication in Gateway Design
When you start building a gateway, one of the first architectural decisions you will run into is how processes talk to each other, and this isn’t just academic. The way components communicate directly shapes throughput, latency, and whether your gateway will become a scalable coordinator or a bottleneck.
Synchronous Communication: Simple but Blocking
In a synchronous world, every call waits for a reply. The gateway asks a service for data, and blocks until it gets a response. It’s straightforward: send a query, wait, get data, repeat. That simplicity has its charm, it makes reasoning about behavior easy, and for very small systems or simple tooling it “just works” without much code overhead.
But a gateway that blocks on every request doesn’t really make sense, or does it? Imagine hundreds of users firing off thousands of queries throughout the day. If the gateway had to wait for each request to fully complete before moving on to the next, everything would grind to a halt. Throughput would collapse, queues would explode, and response times would stretch into the absurd. In that kind of environment, a blocking gateway isn’t just inefficient, it’s simply not an option.
Asynchronous Communication: Parallel by Defaut
Enter asynchronous communication, the game-changer for gateways at scale. With async, the gateway sends a request to a downstream service and doesn’t wait around. Instead of blocking, it continues processing, accepting other client queries, sending more requests, and tracking outstanding work. When results come back, the gateway collects them and finalises the response. This pattern dramatically increases throughput: the gateway isn’t idle while waiting on I/O, and you can overlap slow operations with useful work. Want to query both RDB and HDB at the same time and then merge the results? With asynchronous messaging, that’s the norm rather than the exception.
Deferred Responses: Best of Both Worlds
DefconQ readers should note that many real deployments use a hybrid approach: clients make synchronous requests to the gateway (since they expect a result), but the gateway uses asynchronous calls internally to backends. This lets the gateway juggle work efficiently while preserving a request–response model at the API boundary, synchronous from the client’s perspective but asynchronous under the hood.
The Bigger Picture
Choosing between synchronous and asynchronous isn’t just about RPC (Remote Procedure Call) semantics, it’s about keeping the gateway alive and responsive under load. If your gateway is blocked waiting for every downstream service, you have a serialization point that kills parallelism; if you embrace deferred/asynchronous messaging internally, you unlock far more scalability with relatively modest added complexity.
If you would like to read more about Interprocess Communication (IPC) in KDB/Q, I have written two dedicated blog posts that explore the topic in more detail.
Fundamentals of Interprocess Communication (IPC)
Beyond the Fundamentals: Next Level Interprocess Communications
Resilience and Fault Tolerance
A production-grade gateway shouldn’t fall apart just because a single downstream component has a bad day. In real systems, processes crash, networks hiccup, and services get overloaded, and the gateway is often the first line of defence against all of that. Instead of blindly forwarding requests, a resilient gateway actively monitors the health of its dependencies and adapts its behaviour when things go wrong. If a primary HDB becomes unavailable, the gateway can transparently route requests to a redundant replica. If an RDB is under heavy load, it may choose to return a degraded but still useful response rather than letting queries pile up and time out. And when no viable option exists, the gateway should fail gracefully, returning clear, informative errors instead of leaving users guessing. This is why robust gateways are typically paired with health checks, heartbeats, and well-defined fallback strategies, not just to keep the system running, but to keep it predictable and user-friendly under failure conditions.
Caching in Gateways
One of the most underappreciated, and often overlooked, enhancements in gateway design is smart caching. A well-placed cache allows the gateway to access or store the results of frequently requested queries and serve them directly without hitting downstream services every single time. When combined with sensible invalidation strategies, such as time-to-live (TTL) expiries or event-driven invalidation on data updates, caching can dramatically reduce unnecessary load on RDBs and HDBs. This is especially powerful for predictable or repetitive queries, dashboards, and reference-style lookups where freshness requirements are well understood. Importantly, caching is not about replacing your databases or hiding bad query patterns, it’s about complementing them. Used correctly, gateway-level caching can transform overall system performance, smooth out traffic spikes, and deliver consistently fast response times to end users.
Observability: Because You Can’t Improve What You Don’t Measure
A gateway should never be a black box. As the central coordination point of your KDB/Q stack, it has a unique view of how the system is actually being used, and that insight is far too valuable to ignore. A well-designed gateway exposes clear, actionable metrics such as request volume, latency distributions, error rates, service-level timeouts, and cache hit or miss ratios. These signals allow you to understand not just whether the system is up, but how it behaves under real load. When fed into dashboards and alerting systems, this data becomes the foundation for capacity planning, performance tuning, and rapid incident response. Without observability, you’re flying blind; with it, the gateway becomes one of your most powerful tools for continuously improving reliability and performance.
Aggregating and Normalizing Results
Even when data is distributed across multiple backends, users almost always expect a single, coherent answer. The gateway is the natural place to bring those pieces together. Rather than pushing complexity onto clients, the gateway can aggregate partial responses from different services, normalize schemas, and present a consistent, well-defined output format. This keeps client code simple and decoupled from the underlying data topology. As systems evolve, this aggregation layer becomes increasingly important: new data sources can be introduced, storage formats can change, and legacy services can be retired without breaking consumers. By absorbing that change and enforcing a stable contract at the boundary, the gateway provides continuity over time, and that stability often becomes one of the most valuable and underappreciated features of a well-designed gateway.
Final Thoughts: A Gateway Is More Than a Middleman
A well-designed gateway is not just a thin layer sitting between clients and data, it is the backbone of a responsive, secure, scalable, and maintainable KDB/Q ecosystem. It brings together data access, service health, security, performance, observability, and high-concurrency handling into a single, cohesive control plane. Whether your system serves ten users or ten thousand, the gateway ensures that clients can express what they need in a clean, consistent way, while backend services focus on doing their job efficiently and safely. If you’re building or scaling a real production system, putting a thoughtfully designed gateway in front of it isn’t merely a best practice, it’s a prerequisite for long-term success.
In our next blog post, we will look into a practical, hands-on implementation of a gateway. Until then, stay tuned, and happy coding.